Regression is a supervised machine learning technique which is used to predict continuous values. The ultimate goal of the regression algorithm is to plot a best-fit line or a curve between the data. The three main metrics that are used for evaluating the trained regression model are variance, bias and error. The main difference between regression and classification algorithms that regression algorithms are used to predict the continuous values such as price, salary, age, etc. and classification algorithms are used to predict/classify the discrete values such as Male or Female, True or False, Spam or Not Spam, etc.
This flow will allow you to upload a dataset with labels as an input and train a regression model. The trained model can be visualized. Predictions can be done for selected dataset with trained regressor.
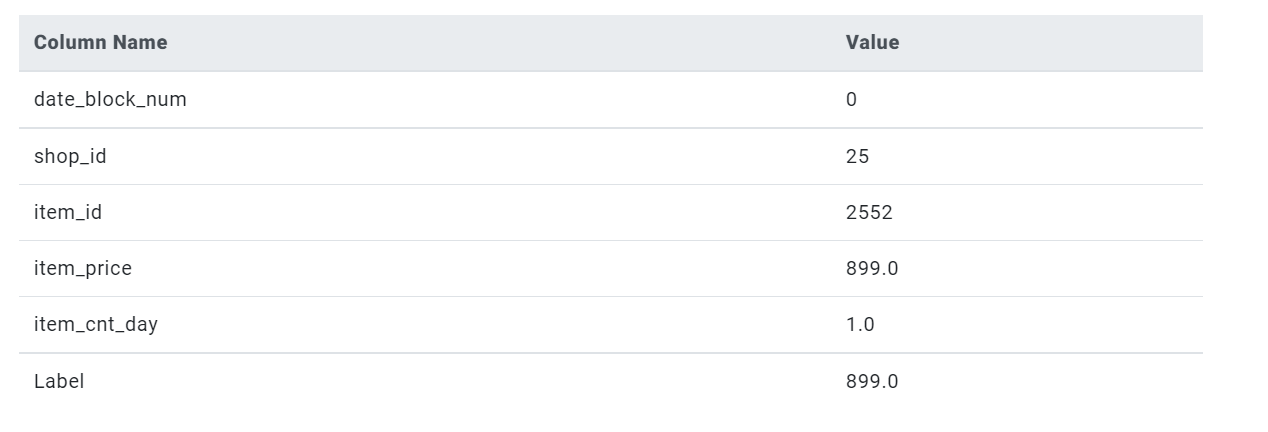
In this example, we will train an AI model using columns such as: date_block_num, shop_id, item_id, item_cnt_day and item_price for a sales prediction purpose. After training the model, it will classify the most important category to the least important category.
Step 1
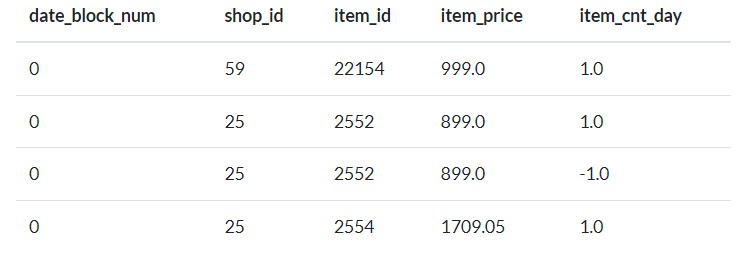
Check for the sales_train.csv file in the appropriate storage path (/DATA/Regression/). If you couldn’t find the csv, upload the proper csv file in that path.


Step 2.
Drag and drop an Inject node and set the payload to timestamp and click done.

Step 3.
Drag and drop a New Advanced Regression Trainer node under Auto AI and name it appropriately to the relevant subject. Here it is named as Walmart Sales Prediction Trainer.
Step 4
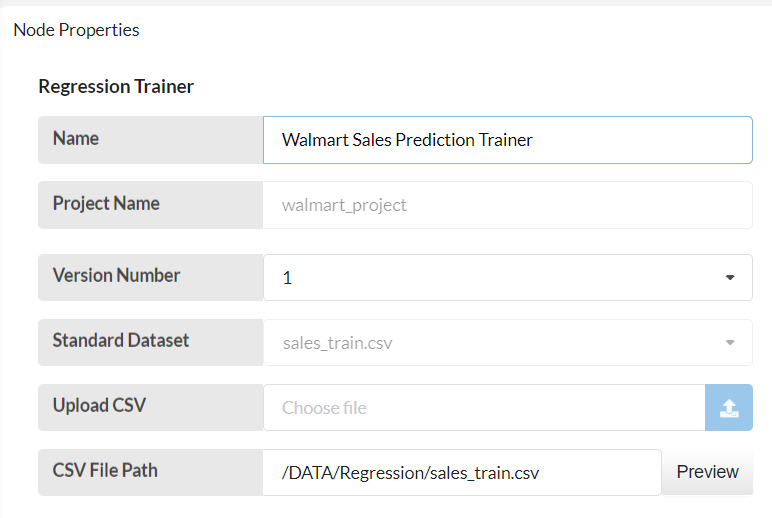
Change the name, project name and choose the dataset on the drop down menu. Check the CSV file path and click on Get Data.
![]()
Step 5.
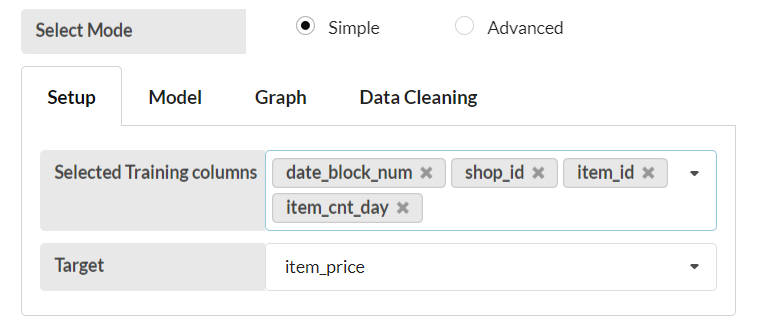
Select all the columns that need to be trained in “Selected Training columns” and select the column that needs to be trained for the target in “Target” according to your dataset.
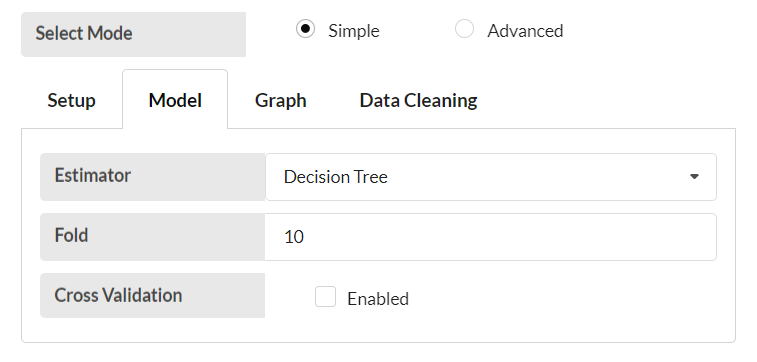
Select a regression estimator in the Model tab.
In this example date_block_num, shop_id, item_id and item_cnt_day are trained in the selected training column while item_price is trained in the target column and also Decision Tree is selected as the estimator.
When you are ready click done and deploy.
Step 6.
Drag and drop Model Visualize node, Regression-Model-tester node, RegressionPredictor AUTOAI node and Prediction Visualize node to the flow. Connect all nodes as shown below and click on deploy.
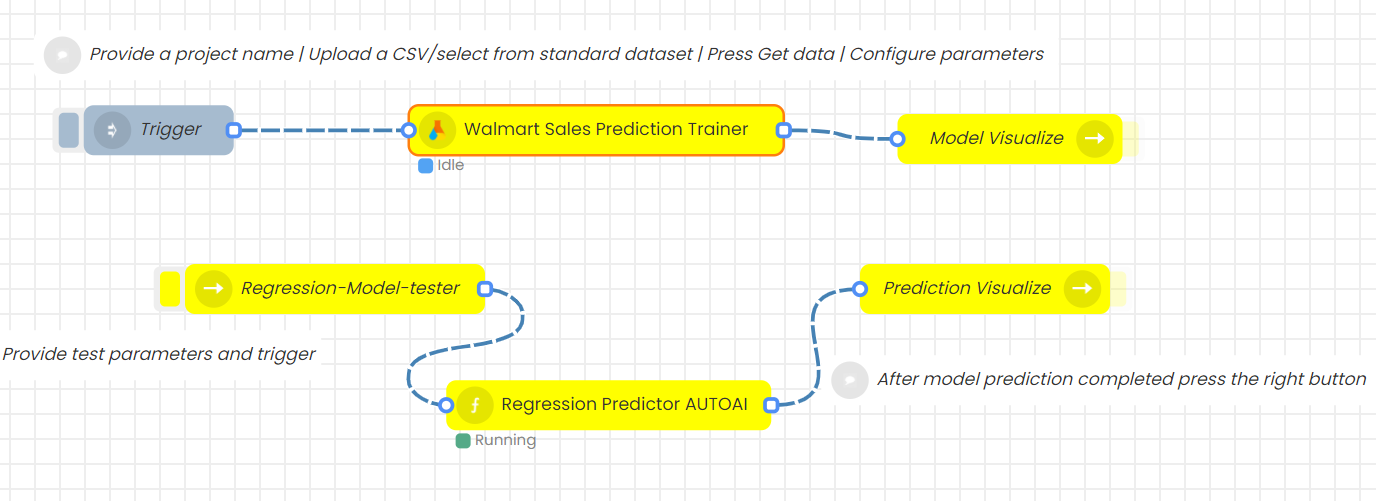
Step 7.
Click on the left side button of Inject node to start training. Progress can be seen in the debug console.
When you see “Model Ready” under the Regression Trainer node, the regression model is trained successfully and can be visualized by triggering Model Visualize node (click on the right side button of the node)
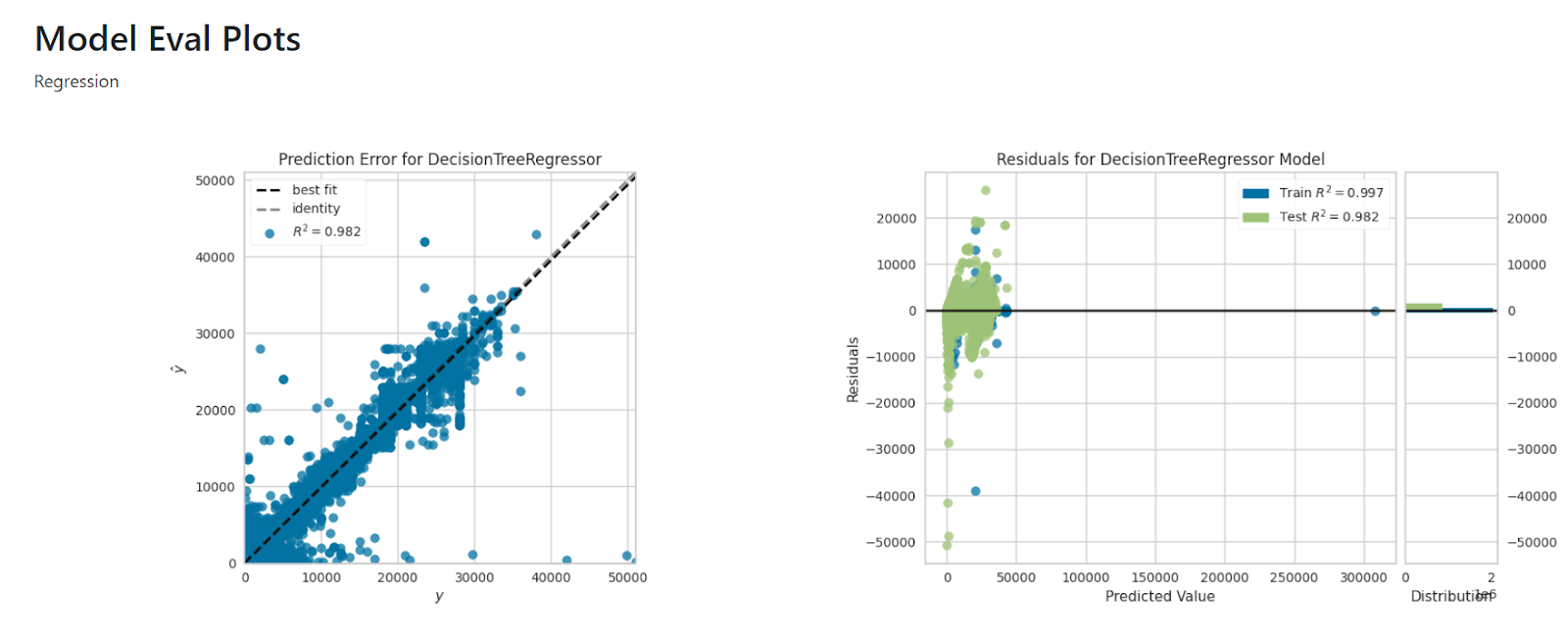
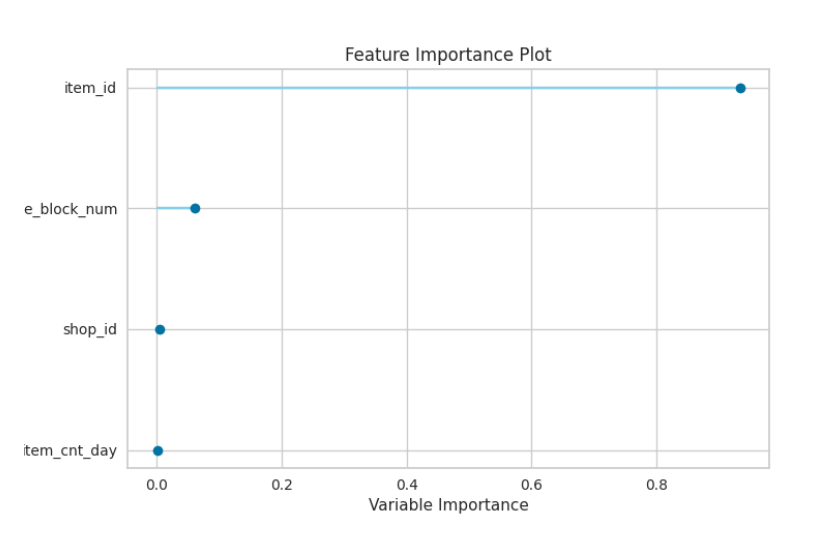
Step 8.
In Regression-Model-tester node, select the project name and set the parameters for the test case. Press done and deploy.
Trigger Regression-Model-tester node (click on the left side button of the node) to predict the test case using the selected model. Trigger the Prediction Visualize node to view the prediction result.